Import Mappings¶
Sub-pages
Introduction¶
Users can map and migrate data directly from the command line or the Providence user interface (under “Import > Data”) into a Providence installation, mapping to the installation profile. An import mapping is a spreadsheet that defines how data is imported into CollectiveAccess. There are many settings and options in the import mapping. This documentation is organized by column, with a description of the function of each column along with the available settings for that column.
Import mappings operate under two basic assumption about your data: that each row in a data set corresponds to a single record and that each column corresponds to a single metadata element. The exception to these rules is an option called treatAsIdentifiersForMultipleRows that will explode a single row into multiple records. This is very useful if you have a data source that references common metadata shared by many pre-existing records in a single row. See the Options section for more details: http://manual.collectiveaccess.org/import/tutorial.html#options-column-5.
Running a data import involves seven basic steps:
- Create an import mapping document (in Excel or Google Sheets) that will serve as a crosswalk between source data and the destination in CollectiveAccess.
- Create a backup of the database by executing a data dump before running the import .
- Run the import from either the command line or the graphical user interface.
- Check the data in CollectiveAccess and look for errors or points of inconsistencies.
- Revise your mapping accordingly.
- Load the data dump so that the system returns to its pre-import state.
- Run the import again.
Sample Mapping¶
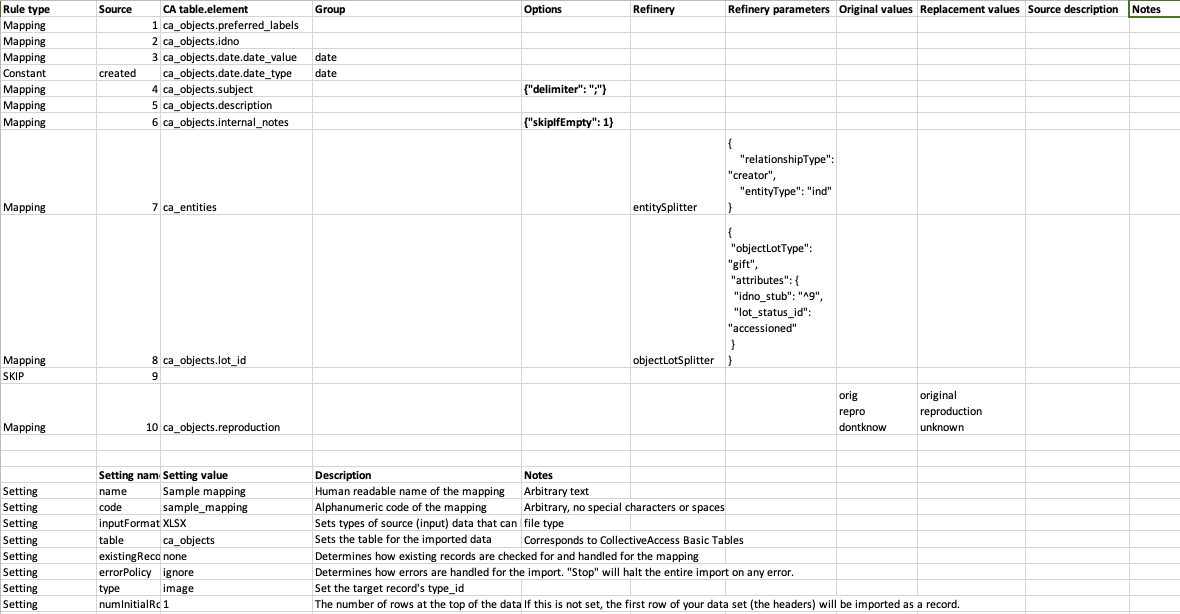
Download these files to see how the Sample Mapping applies to the Sample Data within the Sample Profile. Note that you can upload these to Google Drive and import both import mappings and source data via Google Drive.
Supported Data Input Formats¶
Data can be in: Exif, MODS, RDF, Vernon, FMPDSOResult, MediaBin, ResourceSpace, WordpressRSS, CSVDelimited, FMPXMLResult, MySQL, SimpleXML, WorldCat, CollectiveAccess (CA-to-CA imports), Inmagic, Omeka, TEI, iDigBio, EAD, MARC, PBCoreInst, TabDelimited, Excel, MARCXML, PastPerfectXML, ULAN
A full description of the supported import formats and how they may be referenced is available in the in the Supported File Formats page.
Creating a Mapping¶
Settings¶
Start from the sample worksheet provided above. Settings include the importer name, format of the input data, CollectiveAccess table to import to, and more. This section can be placed at the top or bottom of a mapping spreadsheet with the setting in the first column and parameter in the second. It functions separately from the main column-defined body of the import mapping.
| Setting | Description | Parameter notes | Example |
|---|---|---|---|
| name | Give your mapping a name. | Arbitrary text | My Sample mapping |
| code | Give your mapping an alphanumeric code of the mapping | Arbitrary text, with no special characters or spaces | my_sample_mapping |
| inputFormats | Sets type of source (input) data that can be handled by this import mapping. Values are format codes defined by the various DataReader plugins. | file type | XLSX |
| table | Sets the table for the imported data. If you are importing Objects, set the table to ca_objects. If you are importing Collections, set this to ca_collections, and so on. | Corresponds to the CollectiveAccess basic tables | ca_objects |
| type | Set the Type of record to set all imported records to. If you are importing Objects, what type are they? Photographs, Artifacts, Paintings, etc. This value needs to correspond to an existing value in the the types list. For objects, the list isobject_types. If the import includes a mapping to type_id, that will be privileged and the type setting will be ignored. | CollectiveAccess list item code | image |
| numInitialRowsToSkip | The number of rows at the top of the data set to skip. Use this setting to skip over column headers in spreadsheets and similar data. | numeric value | 1 |
| existingRecordPolicy | Determines how existing records in the CollectiveAccess system are checked for and handled for the mapping. Also determines how records created by the mapping are merged with other instances (idno and/or preferred label) in the data source. (In CollectiveAccess, the primary ID field is “idno” and the title/name field of each record is “preferred_label”.) From version 1.7.9 options to skip, merge or overwrite on internal CollectiveAccess record ids is also supported via the *_on_id options. These options can be useful when re-importing data previously exported from a CollectiveAccess instance. none
skip_on_idno
merge_on_idno
overwrite_on_idno
skip_on_preferred_labels
merge_on_preferred_labels
overwrite_on_preferred_labels
skip_on_idno_and_preferred_labels
merge_on_idno_and_preferred_labels
overwrite_on_idno_and_preferred_labels
merge_on_idno_with_replace
merge_on_preferred_labels_with_replace
merge_on_idno_and_preferred_labels_with_replace
skip_on_id
merge_on_id
merge_on_id_with_replace
overwrite_on_id
|
none | |
| ignoreTypeForExistingRecordPolicy | If set record type will be ignored when looking for existing records as specified by the existing records policy. | 0 or 1 | 0 |
| mergeOnly | If set data will only be merged with existing records using the existing records policy and no new records will be created. Available from version 1.7.9. | 0 or 1 | 0 |
| dontDoImport | If set then the mapping will be evaluated but no rows actually imported. This can be useful when you want to run a refinery over the rows of a data set but not actually perform the primary import. | 0 or 1 | 0 |
| basePath | For XML data formats, an XPath expression selecting nodes to be treated as individual records. If left blank, each XML document will be treated as a single record. | Must be a valid Xpath expression | /export |
| locale | Sets the locale used for all imported data. Leave empty or omit to use the system default locale. Otherwise set it to a valid locale code (Ex. en_US, es_MX, fr_CA). | Must be a valid ISO locale code. | en_US |
| errorPolicy | Determines how errors are handled for the import. Options are to ignore the error, stop the import when an error is encountered and to receive a prompt when the error is encountered. Default is to ignore. | ignore stop | ignore |
Rule Types (Column 1)¶
Each row in the mapping must have a rule defined that determines how the importer will treat the record. Available rules are:
| Rule type | Description |
|---|---|
| Mapping | Maps a data source column or table.field to a CollectiveAccess metadata element. Mappings can carry refineries (see below). |
| SKIP | Use SKIP to ignore a data source column or table.field. |
| Constant | Set a data source column or table.field to an arbitrary constant value. Include the chosen value in the Source column on the mapping spreadsheet. Matches on CollectiveAccess list item idno. |
| Rule | Performs actions during the import (such as skipping or setting data) based on conditional expressions. Made up of two parts: “Rule triggers” and “Rule actions.” TEST See Rules page for more information: Rules |
| Setting | Sets preferences for the mapping (see below). |
Source (Column 2)¶
The source column sets which column from the data source is to be mapped or skipped. You can also set a constant data value, rather than a mapping, by setting the rule type to “constant” and the source column as the value or list item idno from your CollectiveAccess configuration.
An explanation of the most common sources is below. A full description of the supported import formats and how they may be referenced is available in the in the Supported File Formats page.
| Type | Method for setting the source column |
|---|---|
| Spreadsheets | You must convert column letters to numbers. For example, if you want to map Column B of an Excel spreadsheet, you list the Source as 2. (A = 1, B = 2, C = 3, and so on.) Column B of your source data would be pulled. If on the other hand, you wish to skip this column, you would set the Rule Type to Skip and the source value to 2. |
| XML | Set the Source column to the name of the XML tag, proceeded with a forward slash (i.e. /Sponsoring_Department or /inm:ContactName) |
| XPath | XPath is a query language for selecting nodes and computing values from an XML document. It is supported for “Source” specification when importing XML. W3C offers a basic tutorial for writing XPath expressions. |
| MARC | Like other XML formats, the Source value for MARC XML fields and indicators can be expressed using XPATH. |
| FMPXML/RESULT | FileMakerPro XMLRESULT. A few things to note here due to inclusion of invalid characters in field names in certain databases (i.e. ArtBase). See Supported File Formats for rules for Source Field name rules. |
Note
Excel Tip: Translating A, B, C… to 1, 2, 3… can be time-consuming. Excel’s preferences allow you to change columns to display numerically rather than alphabetically. Go to Excel Preferences and select “General.” Click “Use R1C1 reference style.” This will display the column values as numbers.
Special sources
A few special sources are available regardless of the format of the data being imported. These values can be useful for disambiguating the sources of data within CollectiveAccess after import.
Sometimes it’s important to know, for example, which row from an Excel data set a record came from because there’s not enough other data to disambiguate for testing, etc. “Special sources” addresses this by letting you map _row_ to somewhere like internal notes. To do this you include _row_ instead of a number in the source column of your mapping.
| Source | Description |
|---|---|
__row__ |
The number of the row being imported. |
__source__ |
The name of the file being imported. For files imported through the web interface this will be a server-side temporary filename, not the original name of the file. |
__filename__ |
The original name of the file, when available. If the original name of the file is not available (because the uploading web browser did not report it, for instance) then the value for __source__ is returned. |
__filepath__ |
The full path on the server to the file being imported. |
__now__ |
The current date and time. (Available from version 1.7.9). |
CA_table.element (Column 3)¶
This column declares the metadata element in the “table” set in Settings where the data in the source column will be mapped to in CollectiveAccess. If you are setting the source to Skip you do not need to complete this step. If you are mapping data or applying a constant value, you need to set the destination by adding the ca_table.element_code in this column.
CA_table corresponds to the CollectiveAccess basic tables, while element_code is the unique code you assigned to a metadata element in your CA configuration, or an intrinstic field in CA. For example, to map a Title column from your source data into CollectiveAccess, set the CA table.element as ca_objects.preferred_labels
Mapping to Containers
A Container is a metadata element that contains sub-elements. In order to import to specific sub-elements within a Container, you must cite the element codes for both the Container and the code for the sub-element: ca_table.container_code.element_code.
Example: a Date field might actually be a container with two sub-elements: a date range field for the date itself, and a date type drop-down menu to qualify the date. In this case, we would import the date from our source data as:
ca_objects.date.date_value
ca_objects.date.date_type
To map the two of these into the same container, use groups. See more in Group (Column 4) .
Mapping to Related Tables
Data will often contain references to related tables, such as related entities, related lots, related collections, related storage locations, and so on. In order to import data of one table (like ca_objects) while also creating and related records of other tables (like ca_entities), you will need to use refineries.
When your mapping includes references to a table outside the table set in the “table” Settings, you usually just need to cite the table name in this column (example: ca_entities). Then set the details in the refineries column. The exception to this is when you are creating Lot records. In this case, you set the ca_table.element_code to ca_objects.lot_id.
Group (Column 4)¶
In many cases, data will map into corresponding metadata elements bundled together in a container. To continue the example above, a common container is Date, where there are actually two metadata elements - one for the date itself, and another the date’s type (Date Created, Date Accessioned, etc.). Let’s say in your source data there is one column that contains date values, while the next column over contains the date types.
Declaring a Group is simple. Just assign a name to each line in mapping column 4 that is to be mapped into a single container.
If Source “2” is mapping to ca_objects_date.date_value, and Source “3” is mapping to ca_objects.date.date_type, give each line the group name “Date” This will tell the mapping that these two lines are going to a single container - and won’t create a whole new container for each. Any word will work, it just has to be the same for each element that goes into the container.
Options (Column 5)¶
Options can be used to set a variety of conditions on the import, process data that needs clean-up, or format data with templates. This example shows some of the more commonly used options. See the complete list of options: Mapping Options
| Option | Description | Notes | Example |
|---|---|---|---|
| delimiter | Delimiter to split repeating values on. | {"delimiter": ";"} |
|
| hierarchicalDelimiter | Delimiter to use when formatting hierarchical paths. This option is only supported by sources that have a notion of related data and relationship types, most notably (and for now only) the CollectiveAccessDataReader. | {"hierarchicalDelimiter: " ➜ "} |
|
| formatWithTemplate | Display template to format value with prior to import. Placeholder tags may be used to incorporate data into the template. Tags always start with a “^” (caret) character. For column-based import formats like Excel and CSV the column number is used to reference data. For XML formats an XPath expression is used. While templates are tied to the specific source data element being mapped, they can reference any element in the import data set. For example, in an import from an Excel file, the template used while mapping column 2 (tag ^2 in the template) may also use tags for any other column. | There is no requirement that a template include a tag for the column being mapped. The template can reference any element in the current row, without restriction. | {"formatWithTemplate":
"Column 1: ^1; Column 4: ^4"}
|
| applyRegularExpressions | Rewrite source data using a list of Perl compatible regular expressions as supported in the PHP programming language. Each item in the list is an entry with two keys: “match” (the regular expression) and “replaceWith” (a replacement value for matches). “replaceWith” may include numbered back references in the form \n where n is the index of the regular expression parenthetical match group. | “applyWithRegularExpressions” will modify the data value being mapped for both import and comparison. Options that test values, such as “skipIfValue”, will use the modified value unless _useRawValuesWhenTestingExpression_ is set. | {
"applyRegularExpressions": [
{
"match": "([0-9]+)\\.([0-9]+)",
"replaceWith": "\\1:\\2"
},
{
"match": "[^0-9:]+",
"replaceWith": ""
}
]
}
|
| prefix | Text to prepend to value prior to import. | From version 1.7.9 placeholder tags may be used to incorporate import data into the prefix. In previous versions, only static text was supported. | |
| suffix | Text to append to value prior to import. | From version 1.7.9 placeholder tags may be used to incorporate import data into the suffix. In previous versions, only static text was supported. | |
| default | Value to use if data source value is empty. | ||
| restrictToTypes | Restricts the the mapping to only records of the designated type. For example the Duration field is only applicable to objects of the type moving_image and not photograph. | {“restrictToTypes”: [“moving_image”, “audio”]} | |
| filterEmptyValues | Remove empty values from values before attempting to import. | When importing repeating values, all values are imported, even blanks. Setting this option filters out any value that is zero-length. | |
| filterToTypes | Restricts the mapping to pull only records related with the designated types from the source. | This option is only supported by sources that have a notion of related data and types, most notably (and for now only) the CollectiveAccessDataReader. | |
| filterToRelationshipTypes | Restricts the mapping to pull only records related with the designated relationship types from the source. | This option is only supported by sources that have a notion of related data and relationship types, most notably (and for now only) the CollectiveAccessDataReader. | |
| skipIfEmpty | Skip the mapping If the data value being mapped is empty. | {"skipIfEmpty": 1} |
|
| skipRowIfEmpty | Skip the current data row if the data value being mapped is empty. | ||
| skipGroupIfEmpty | Skip all mappings in the current group if the data value being mapped is empty. | ||
| skipIfValue | Skip the mapping If the data value being mapped is equal to any of the specified values. | Comparisons are case-sensitive. | {“skipIfValue”: [“alpha”, “gamma”]} |
| skipRowIfValue | Skip the current data row If the data value being mapped is equal to any of the specified values. | Comparisons are case-sensitive. | {“skipRowIfValue”: [“alpha”, “gamma”]} |
| skipGroupIfValue | Skip all mappings in the current group If the data value being mapped is equal to any of the specified values. | Comparisons are case-sensitive. | {“skipGroupIfValue”: [“alpha”, “gamma”]} |
| skipIfNotValue | Skip the mapping If the data value being mapped is not equal to any of the specified values. | Comparisons are case-sensitive. | {“skipIfNotValue”: [“beta”]} |
| skipRowIfNotValue | Skip the current data row If the data value being mapped is not equal to any of the specified values. | Comparisons are case-sensitive. | {“skipRowIfNotValue”: [“beta”]} |
| skipGroupIfNotValue | Skip all mappings in the current group If the data value being mapped is not equal to any of the specified values. | Comparisons are case-sensitive. | {“skipGroupIfNotValue”: [“beta”]} |
| skipIfExpression | Skip mapping if expression evaluates to true. All data in the current row is available for expression evaluation. By default, data is the “raw” source data. To use data rewritten by replacement values and applyRegularExpressions in your expression evaluation, set the _useRawValuesWhenTestingExpression_ to false. | {“skipIfExpression”: “^14 =~ /kitten/”} | |
| skipRowIfExpression | Skip data row if expression evaluates to true. Data available during evaluation is subject to the same rules as in _skipIfExpression_. | {“skipRowIfExpression”: “wc(^14) > 10”} | |
| skipGroupIfExpression | Skip mappings in the current group if expression evaluates to true. Data available during evaluation is subject to the same rules as in _skipIfExpression_. | {“skipGroupIfExpression”: “wc(^14) > 10”} | |
| skipIfDataPresent | Skip mapping if data is already present in CollectiveAccess. | Available from version 1.7.9 | |
| skipIfNoReplacementValue | Skip mapping if the value does not have a replacement value defined. | Available from version 1.7.9 | |
| skipWhenEmpty | Skip mapping when any of the listed placeholder values are empty. | Available from version 1.7.9 | {“skipWhenEmpty”: [“^15”, “^16”, “^17”]} |
| skipWhenAllEmpty | Skip mapping when all of the listed placeholder values are empty. | Available from version 1.7.9 | {“skipWhenAllEmpty”: [“^15”, “^16”, “^17”]} |
| skipGroupWhenEmpty | Skip group when any of the listed placeholder values are empty. | Available from version 1.7.9 | {“skipGroupWhenAllEmpty”: [“^15”, “^16”, “^17”]} |
| skipGroupWhenAllEmpty | Skip group when all of the listed placeholder values are empty. | Available from version 1.7.9 | {“skipGroupWhenAllEmpty”: [“^15”, “^16”, “^17”]} |
| skipRowWhenEmpty | Skip row when any of the listed placeholder values are empty. | Available from version 1.7.9 | {“skipRowWhenAllEmpty”: [“^15”, “^16”, “^17”]} |
| skipRowWhenAllEmpty | Skip row when all of the listed placeholder values are empty. | Available from version 1.7.9 | {“skipRowWhenAllEmpty”: [“^15”, “^16”, “^17”]} |
| useRawValuesWhenTestingExpression | Determines whether data used during evaluation of expressions in _skipIfExpression_, _skipRowIfExpression_ and similar is raw, unaltered source data or data transformed using replacement values and/or regular expressions defined for the mapping. The default value is true – use unaltered data. Set to false to use transformed data. (Available from version 1.7.9) | Available from version 1.7.9 | {“useRawValuesWhenTestingExpression”: false} |
| maxLength | Defines maximum length of data to import. Data will be truncated to the specified length if the import value exceeds that length. | ||
| relationshipType | A relationship type to use when linking to a related record. | The relationship type code is used. This option is only used when directly mapping to a related item without the use of a splitter. | |
| convertNewlinesToHTML | Convert newline characters in text to HTML <BR/> tags prior to import. | ||
| collapseSpaces | Convert multiple spaces to a single space prior to import. | ||
| useAsSingleValue | Force repeating values to be imported as a single value concatenated with the specified delimiter. | This can be useful when the value to be used as the record identifier repeats in the source data. | |
| matchOn | List indicating sequence of checks for an existing record; values of array can be “label” and “idno”. Ex. [“idno”, “label”] will first try to match on idno and then label if the first match fails. | This is only used when directly mapping to a related item without the use of a splitter. | |
| truncateLongLabels | Truncate preferred and non-preferred labels that exceed the maximum length to fit within system length limits. | If not set, an error will occur if overlength labels are imported. | |
| lookahead | Number of rows ahead of or behind the current row to pull the import value from. | This option allows you to pull values from rows relative to the current row. The value for this option is always an integer indicating the number of rows ahead or (positive) or behind (negative) to jump when obtaining the import value. This setting is effective only for the mapping in which it is set. | |
| useParentAsSubject | Import parent of subject instead of subject. | This option is primarily useful when you are using a hierarchy builder refinery mapped to parent_id to create the entire hierarchy (including subject) and want the bottom-most level of the hierarchy to be the subject rather than the item that is the subject of the import. | |
| treatAsIdentifiersForMultipleRows | Explode import value on delimiter and use the resulting list of values as identifiers for multiple rows. | This option will effectively clone a given row into multiple records, each with an identifier from the exploded list. | |
| displaynameFormat | Transform label using options for formatting entity display names. Default is to use value as is. | Other options are surnameCommaForename, forenameCommaSurname, forenameSurname. See DataMigrationUtils::splitEntityName(). | |
| mediaPrefix | Path to import directory containing files references for media or file metadata attributes. | This path can be absolute or relative to the configured CollectiveAccess import directory, as defined in the app.conf _batch_media_import_root_directory_ directive. | |
| matchType | Determines how file names are compared to the match value. | Valid values are STARTS, ENDS, CONTAINS and EXACT. (Default is EXACT). | |
| matchMode | Determines whether to search on file names, enclosing directory names or both. | Valid values are DIRECTORY_NAME, FILE_AND_DIRECTORY_NAMES and FILE_NAME. (Default is FILE_NAME). | |
| errorPolicy | Determines how errors are handled for the mapping. Options are to ignore the error, stop the import when an error is encountered and to receive a prompt when the error is encountered. | Valid values are _ignore_ and _stop_. | |
| add | Always add values after existing ones even if existing record policy mandates replacement (Eg. merge_on_idno_with_replace, Etc.) | Available from version 1.7.9 | |
| replace | Always replace values, removing existing, ones even if existing record policy does not mandate replacement (Eg. is not merge_on_idno_with_replace, Etc.). | Available from version 1.7.9 |
In the example above, multiple subject values in the same cell that are separated by semi-colons. By setting the delimiter option in the mapping, you are ensuring that these subject values get parsed and imported to discrete instances of the Subject field. Without the delimiter option, the entire string would end up a single instance of the Subject field.
Refineries (Column 6-7)¶
Refineries fall into one of 5 camps: Splitters, Makers, Joiners, Getters and Builders. Each framework is designed to take a specific data format and transform it via a specific behavior as it is imported into CollectiveAccess. See the Refineries page for a complete list of refineries: Refineries
Splitters¶
Splitter refineries can either create records, match data to existing records (following a mapping’s existingRecordPolicy) or break a single string of source data into several metadata elements in CollectiveAccess. Splitters for relationships are used when several parameters are required, such as setting a record type and setting a relationship type. Using the entitySplitter, a name in a single location (i.e. column) in a data source can be parsed (into first, middle, last, prefix, suffix, et al.) within the new record. Similarly the measurementSplitter breaks up, for example, a list of dimensions into to a CollectiveAccess container of sub-elements. “Splitter” also implies that multiple data elements, delimited in a single location, can be “split” into unique records related to the imported record. See the Splitters page for a complete list of splitters.
Makers¶
Maker refineries are used to create CollectiveAccess tour/tour stop, object lot/object and list/list item pairings. These relationships are different than other CollectiveAccess relationships for two reasons. Firstly, they don’t carry relationship types. Secondly, these relationships are always single to multiple: a tour can have many tour stops, but a tour stop can never belong to more than one tour. Similarly an object can never belong to more than one lot. List items belong to one and only one list. The Maker refinery is used for these specific cases where “relationshipType” and other parameters are unnecessary.
Joiners¶
In some ways Joiners are the opposite of Splitters. An entityJoiner refinery is used when two or more parts of a name (located in different areas of the data source) need to be conjoined into a single record. The dateJoiner makes a single range out of two or more elements in the data source.
Getters¶
Getters are designed specifically for MYSQL data mappings. These refineries map the repeating source data through the linking table to the correct CollectiveAccess elements.
Builders¶
Builders create an upper hierarchy above the to-be-imported data. Note that Splitters also create upper hierarchies with the parent parameter, but they do so above records related to the imported data. For example, let’s say you were importing ca_collections and wanted to map a “Series” and “Sub-series” above imported “File” data. You’d use the collectionHierarchyBuilder refinery. However, if you were importing ca_objects and wanted to relate a “File” while building an upper hierarchy of “Series” and “Sub-series” you would use the collectionSplitter and the parent parameter. See the Builders page for a complete list of builders: Builders
Original values and Replacement values (Columns 8-9)¶
In some cases, particularly when you are mapping to a list element, you may need the mapping to find certain values in your source data and replace them with new values upon import. In the Original Value column, you may state all values that you wish to have replaced. Then, in the Replacement Value column, set their replacements. You can add multiple values to a single cell, so long as the replacement value matched the original value line by line. Using the Original and Replacement columns is sufficient for transforming a small range of values. But for really large transformation dictionaries, use the option “transformValuesUsingWorksheet” instead: http://manual.collectiveaccess.org/import/mappings.html#transform-values-using-worksheet.
Source Description & Notes (Columns 10 & 11)¶
These two columns are used to clarify the source and purpose of each line in the mapping and are optional. Source Description is generally a plain text label or name for the original source column to allow for easy reference to which fields are being mapped (or skipped) in the mapping. Notes provides a space to explain how and why a certain line is mapped in the manner that it is, for example, explaining why a certain value is being omitted or how an entity line is being split and related to the main record.
These fields can be useful for future reference if a mapping is intended to be used repeatedly to be sure that the selected mapping matches the source data.
Importing data¶
Once the import mapping is complete, you are ready to run the import. See the Running an Import page.